27 March 2026
Interactive books with TeXmacs via Docker
I like TeXmacs. There are several difficulties when I use it,
but still, I like the concept: To have one big system that ensures high-quality typesetting and external sessions.
Now, I started writing the books I mentioned in the previous blog entry. For the theological work
I already created a GitHub repo which also contains
a Dockerfile and a script runme.sh (currently only for Debian/Ubuntu systems) if someone
wants to read the book interactively. This means that all examples can be tried and eventually modified
if the reader decides to play with them.
I faced a couple of technical difficulties. First, I learned that the Python module I developed for bibref
requires an official repository. I chose PyPI (Python Package Index) to publish the package
bibref-python officially. Now, the package
can be installed via pip install bibref-python, but I learned that it is much better to
run such package installation steps in a virtual environment. (For Python experts, this is should
be quite evident, but for me, it was not.)
Second, it turned out that communication between TeXmacs and my session plugin works differently in
some cases if I run them via Docker. I am still unsure what exactly the difference was, but finally
I rewrote
the communication protocol to send everything in one chunk, instead of slice the output
in multiple packets. For some strange reason, sometimes only the first few packets arrived and
the rest disappeared.
Third, I had to create the locale definitions manually in Docker to ensure that TeXmacs finds the required
localizations (in my case, for the book, I currently need only Hungarian localization). Otherwise
TeXmacs crashed without using any fallback setting.
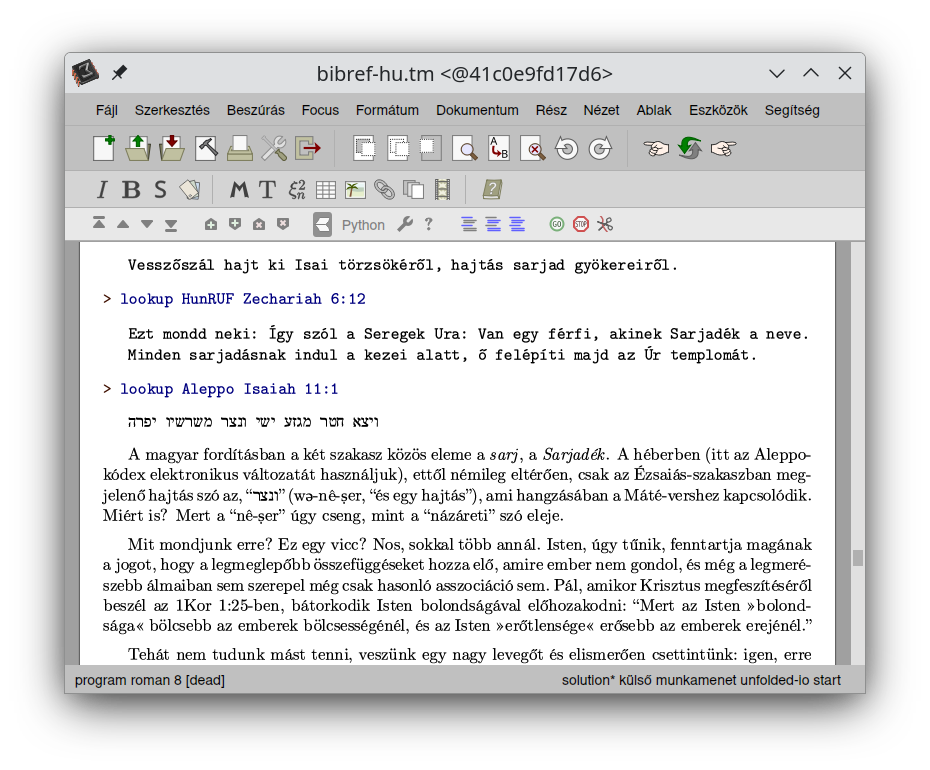
Fourth, I learned that TeXmacs can show Hebrew fonts, so, after I added
bidirectional text handling in the TeXmacs export part in bibref,
I added some code to include the Aleppo Codex via the Dockerfile.
Fifth, I realized that TeXmacs will start with a welcome message, unless it has already been started.
Since I did not want that, I start TeXmacs for the first time with an automated exit (texmacs -q),
and then, for the second run, I load the interactive book.
Sixth, I improved some parts of the Dockerfile by muting some warning messages by enabling non-interactive
run of apt-get, and copied some frequently changing files (including the book itself) from the local
folder by using the COPY command in Docker.
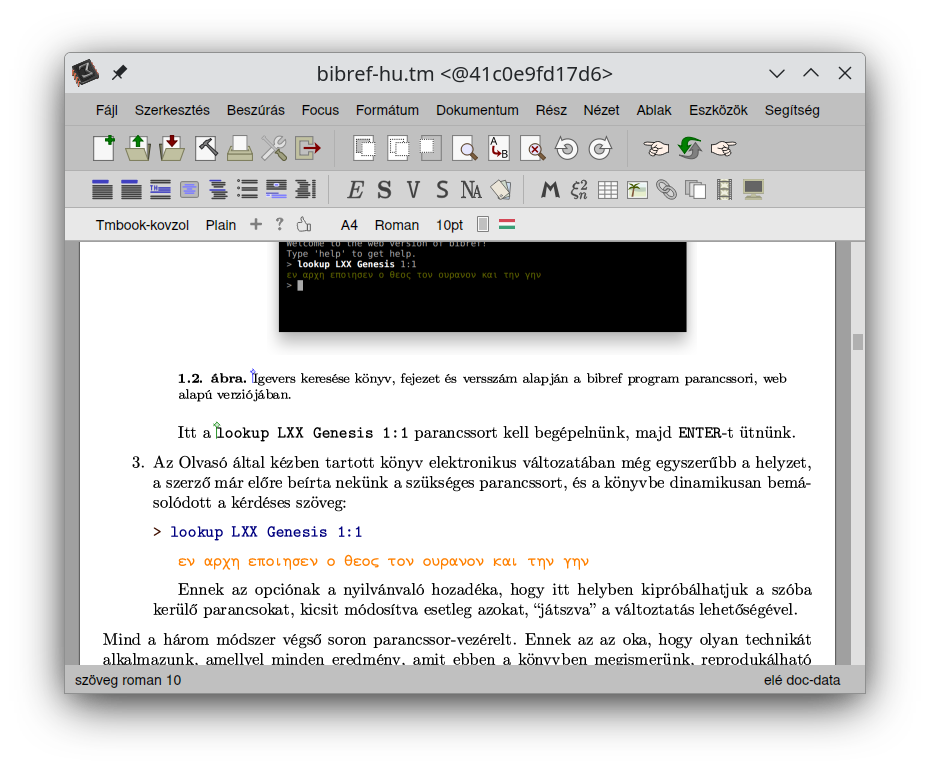
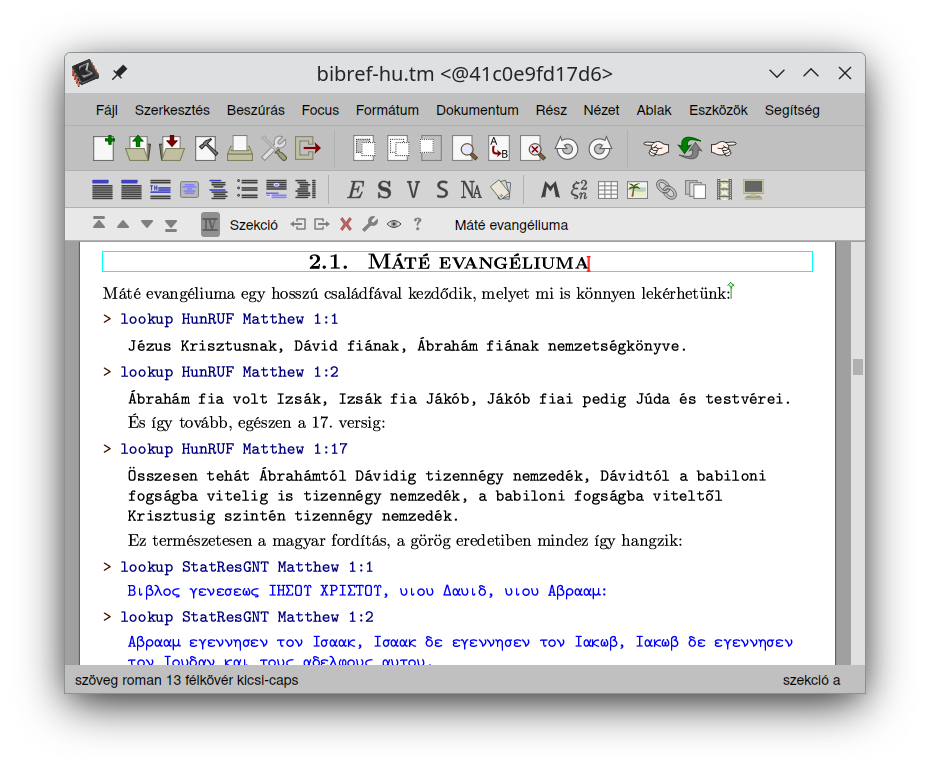
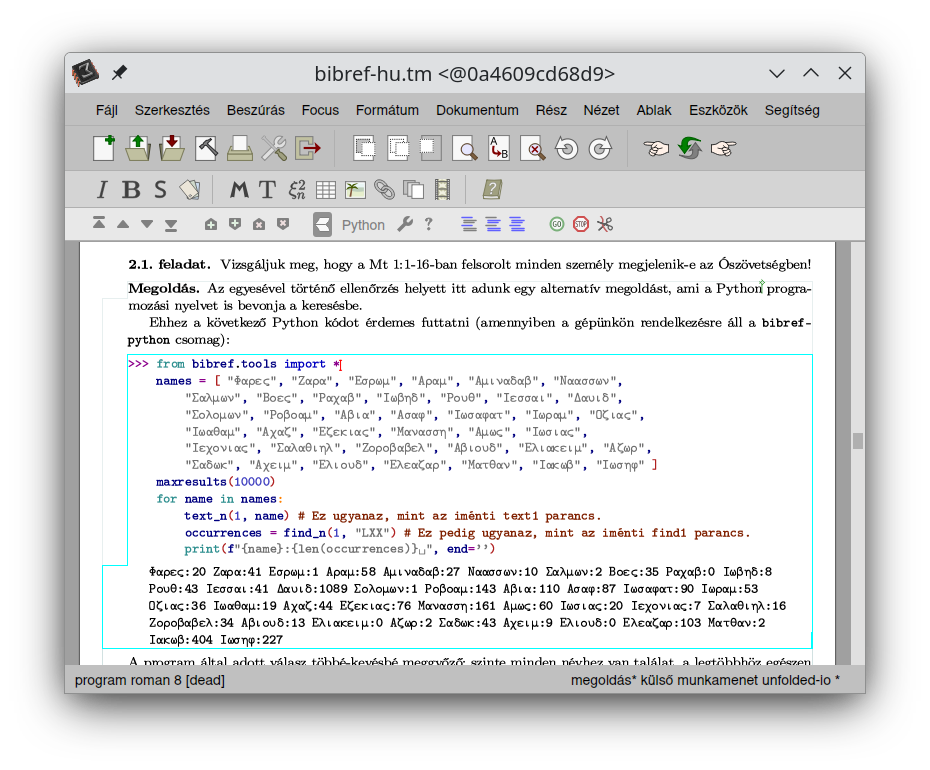
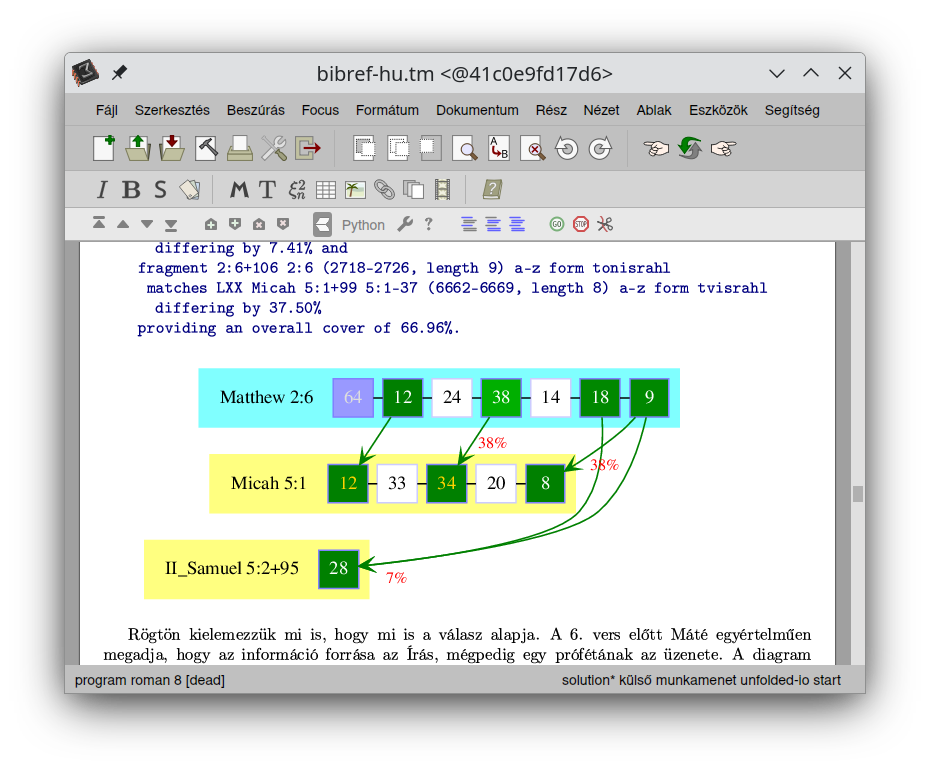
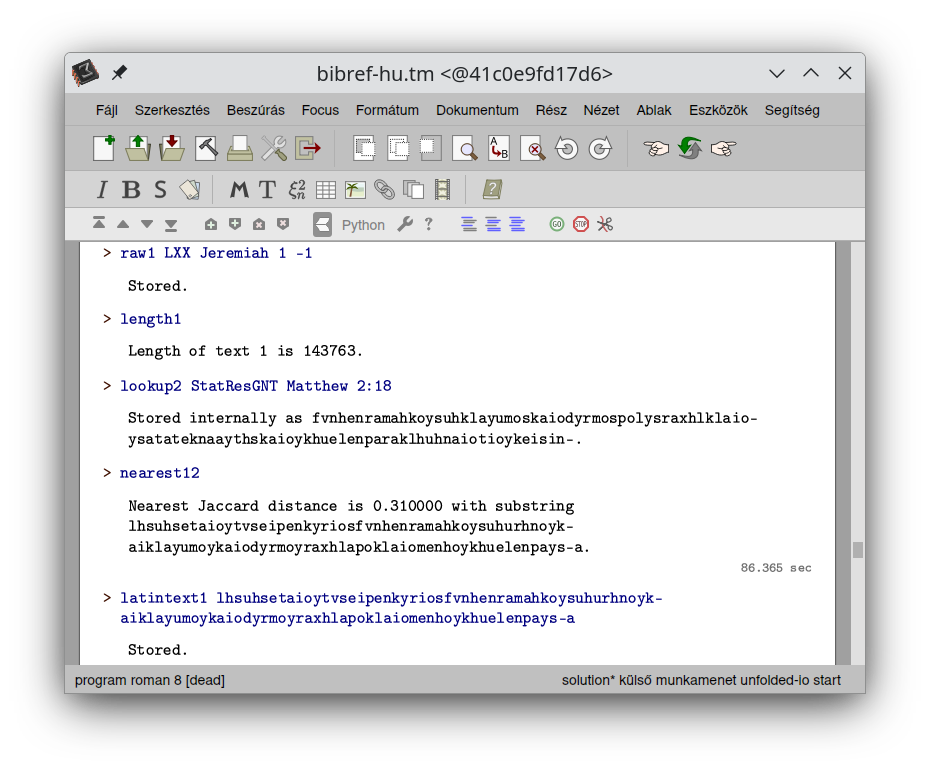
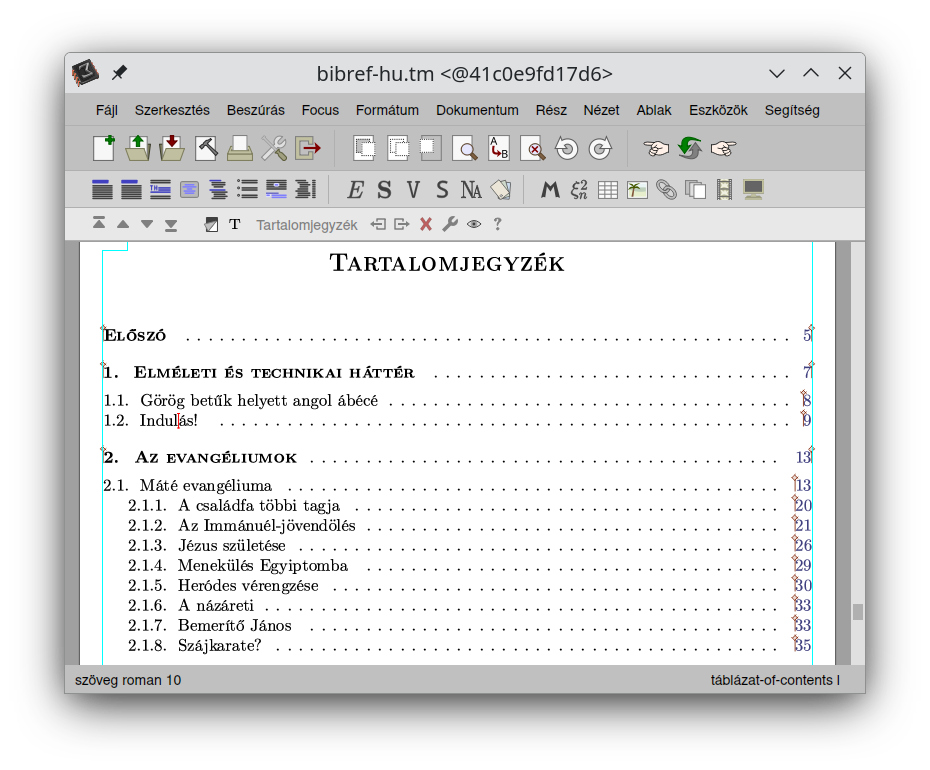
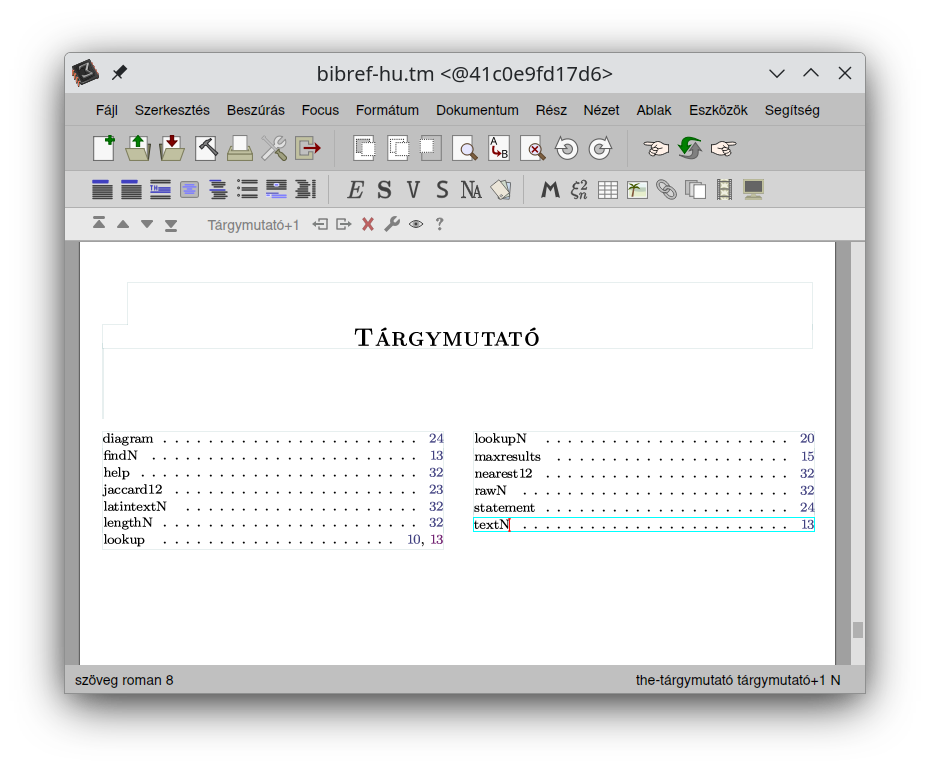
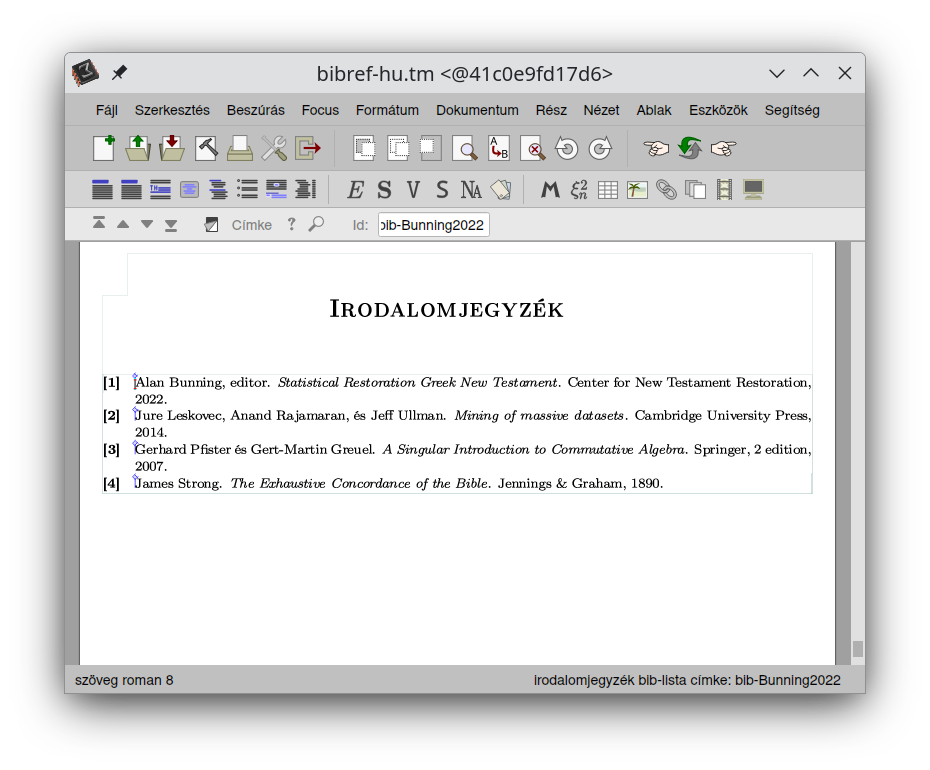
Below are some screenshots about the on-going work. By having the success of setting up a full-featured
interactive book with the possibility of running arbitrary bibref code anytime, also with the option
to run Python code with imported bibref commands, I am managing to produce quite a high number of
pages surprisingly quickly. It is not really about the number of pages but the content, of course,
but anyway: it is a great joy for me to see my plans developing so nicely and in a good shape already.
Continue reading…
- 9 March 2026—TeXmacs plugins
- 15 January 2026—Towards reproducible builds via Docker
- 24 December 2025—Statement diagrams based on LXX 3.2
- 23 December 2025—bibref: Support for LXX 3.2 and StatResGNT 1.4, and some technical infos
- 30 October 2025—GeoGebra Discovery reaches 2000 installations via Snapcraft
- 23 August 2025—bibref: German language support
- 14 August 2025—Module LXX can be upgraded from 3.0 to 3.2 just with little pain
- 13 August 2025—GraphViz as a WebAssembly module
- 10 July 2025—Connecting ISBTF's LXX-NT database with bibref
- 5 July 2025—JGEX via CheerpJ
- 20 April 2025—An online Qt GUI version of bibref
- 29 March 2025—An allusion on Palm Sunday
- 8 March 2025—Statement analysis in bibref
- 7 March 2025—Developing C++ code for desktop and web with cmake
- 7 February 2025—Update to LXX 3.0: Part 2
- 5 February 2025—Deuterocanonical books in the bibref project
- 23 January 2025—Statements connecting LXX and StatResGNT
- 6 January 2025—Treasure of Count Goldenwald
- 2 January 2025—Statements on Bible references: Part 2
- 22 August 2024—Compiling and running bibref-qt on Wine
- 5 August 2024—Statements on Bible references
- 30 July 2024—Difficulty of geometry statements
- 11 March 2024—Qt version of bibref
- 2 January 2024—xaos.app
- 10 December 2023—JGEX 0.81 (in Hungarian)
- 11 November 2023—Debut of GNU Aris in WebAssembly
- 30 August 2023—XaoS in WebAssembly
- 31 July 2023—Statistical Restoration Greek New Testament
- 16 April 2023—Tube amoeba
- 15 April 2023—Torus puzzle
- 19 September 2022—Stephen's defense speech
- 25 August 2022—A general visualization
- 23 August 2022—Long false positives
- 31 July 2022—Isaiah, a second summary
- 25 July 2022—Matthew, a summary
- 17 July 2022—On the Wuppertal Project, concerning Matthew
- 28 June 2022—Terminals on the web
- 7 April 2022—A summary
- 2 April 2022—Compiling Giac via MSYS2/CLANG32
- 30 March 2022—Isaiah: Part 7
- 23 March 2022—Isaiah: Part 6
- 15 March 2022—Isaiah: Part 5
- 7 March 2022—Isaiah: Part 4
- 2 March 2022—Isaiah: Part 3
- 26 February 2022—Isaiah: Part 2
- 19 February 2022—Isaiah: Part 1
- 15 February 2022—A classification of structure diagrams
- 12 February 2022—Supporting logic with technology: Part 2
- 7 February 2022—The Psalms: Part 2
- 6 February 2022—The Psalms
- 5 February 2022—A summary on the Romans
- 3 February 2022—Non-literal matches in the Romans: Part 2
- 2 February 2022—Non-literal matches: Jaccard distance
- 1 February 2022—Literal matches: the minunique and getrefs algorithms
- 31 January 2022—Literal matches: minimal uniquity and maximal extension
- 26 January 2022—Non-literal matches in the Romans
- 24 January 2022—Developing Giac with Qt Creator on Windows
- 23 January 2022—A student of Gamaliel's
- 20 January 2022—Reproducibility and imperfection
- 17 January 2022—Order in chaos
- 12 January 2022—Web version of bibref
- 2 November 2021—Supporting logic in function calculus
- 28 October 2021—Proving inequalities
- 27 October 2021—Discovering geometric inequalities
- 1 October 2021—Web version of Tarski
- 9 July 2021—Embedding realgeom in GeoGebra
- 26 January 2021—ApplyMap
- 25 January 2021—Comparison improvements
- 29 December 2020—Pete-Dőtsch theorem
- 18 November 2020—Ellipsograph of Archimedes as a simple LEGO construction
- 17 November 2020—Offsets of a trifolium
- 11 November 2020—Explore envelopes easily!
- 31 October 2020—Points attached to an algebraic curve…
- 19 October 2020—Detection of perpendicular lines…
- 6 October 2020—Better language support…
- 29 September 2020—A new GeoGebra version with better angle bisectors…
- 28 September 2020—I restart my blog…

|
Zoltán Kovács Linz School of Education Johannes Kepler University Altenberger Strasse 69 A-4040 Linz |