2 January 2025
Statements on Bible references in form of a sentence: Part 2
Four months ago, in the middle of the summer holidays,
I was working on the plans
of a system to improve the reports of my Bible research project. Now, in the middle
of the winter holidays, I am happy to announce that the first milestones have been reached.
The prototype of a new bibref version can be downloaded at
GitHub.
In this post I give an overview on the steps achieved.
Technological challenges
My first idea
was to use ANTLR to define the grammar for the BRST language I introduced.
I ran into two problems.
First, ANTLR has poor support for C++ (it's definitely a Java-based system),
and, on Ubuntu Linux, correct detection and overriding
of pre-installed ANTLR versions for the C++ bindings
were inconvenient. Second, some part of the grammar was defined incorrectly, and I was unable
to find where my mistake was.
So, after a couple of weeks of unsuccessful attempts I changed to the flex/bison machinery.
They are oldie but goldie, with lots of good documentation. In fact, I ran into several
difficulties again, but at least I was able to find some more help to get a working solution.
As of today, the code is still not perfect: the
lexer
is too long (7 kB) and unelegant, the
parser
contains inline C calls (so the parser logic and the semantic check are mixed), therefore the parser
code is very long (41 kB). I also had to change the grammar a bit because of an ambiguous
definition in the language, maybe it was again my fault, but I did not want to put more
effort to work on the language. There are still minor questions I should address someday,
e.g. to find out the column position of the input properly.
Also, I'm hoping that the code could be splitted
into smaller C files and some C functions can be shortened by merging some similar code.
By the way, bibref is written in C++, so the flex/bison C machinery was something I tried
to change quickly into a C++ approach. Indeed, flex/bison allows you to create C++ code,
but it looked technically too difficult for me at first sight, so I decided to stay with C
on the flex/bison side and write the required wrappers to connect the C++ parts. This
was very challenging, and sometimes a real nightmare with mystical segmentation faults
and string conversion errors. Finally I learned a lot on the internals of C/C++ communication,
and also I started to use debugger tools like gdb
and valgrind much more frequently.
Another challenge was that my laptop (running Ubuntu Linux 24.04) had technical problems.
During the last few weeks I had to change my workstation to a Windows. A positive outcome
of this was that I had to keep in mind that bibref must be a platform independent application.
Therefore, I wanted to unify the codebase for all platforms. I learned a lot how to do that
by using CMake.
It has support not only for the flex/bison preparations but also for the Qt
configuration which was an essential part of the work.
bibref already had a Qt user interface. For the visual diagrams, however, a graphical
interface was unavoidable. On the one hand, Qt has been proven to be a very good option in
the syntax highlighting support for the Statement Editor. On the other hand, visualization
of directed acyclic graphs
is also possible without running any external application.
This is more or less nicely documented, but I had to face the problem that the SVG support
is far from being complete in Qt.
The SVG output was required for this scenario because my old code from Python was difficult to re-use.
The old approach used LaTeX and TikZ.
I studied a couple of possibilities if my old method
would work in the new scenario, including an embedded LaTeX system, or embedding just
TikZ, and so on. Finally, these options had to be rejected because of the state of the
art of the available third party software. Finally I found two better options,
one was ODGF: it is a sophisticated C++ library,
but not very well known and well supported. The other option looked simpler:
to use GraphViz, it has C bindings and can
be integrated quite smoothly in a CMake workflow.
Of course, it was not that smooth I expected. The biggest challenge was to define
the graph layout as accurate as possible, to keep the previous visualization
as much as GraphViz can support. Also, on Windows, linking the final executable
was a kind of tricky because GraphViz wants to use certain plugins to load
a dot file or to render the output into SVG. Luckily, the above mentioned 41 kB of code
in the parser already generates the whole input for GraphViz during a successful
run. This shows that the choice of GraphViz was actually a good idea.
The user interface
The new version does not come with a detailed tutorial, so let me give some hints
on using the new user interface. A new menu option was added to the Quotation menu:
Statement... By default, this option is disabled. Only after loading the
Bible database (in the File menu, by choosing Add Books) it becomes enabled.
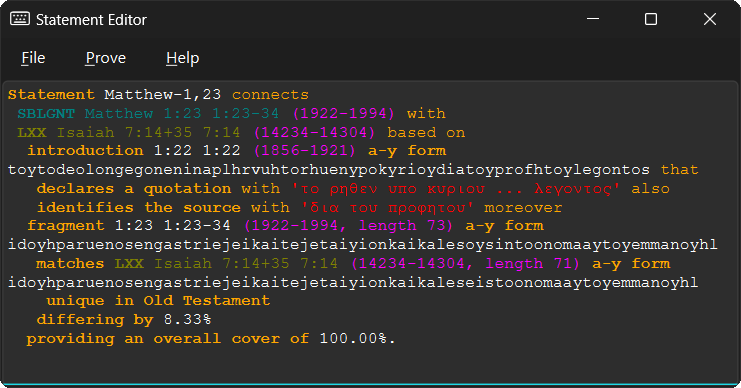
The Statement Editor window contains an example BRST statement on startup.
Currently it is hardcoded (it explains the quotation from
Matthew 1:23), but the text
can be freely edited. Also, another example can be loaded via File > Open...
from the statements
folder. More than 200 examples are provided that were
exported from the SQL database and carefully checked by hand during the last years.
(However, there can still be some bugs in them! I will start another round to double-check them soon.)
If you are brave enough to start a statement from scratch, it is also possible
to clear the window by choosing File > New, but maybe it is
too challenging for most users because the language has a very strict grammar,
even if each statement is a grammatically correct English sentence. (I hope!)
Here is an example for such a statement. Note that language used is not completely
the same I provided four months ago, but just mostly:
Statement Matthew-1,23 connects SBLGNT Matthew 1:23 1:23-34 (1922-1994) with LXX Isaiah 7:14+35 7:14 (14234-14304) based on introduction 1:22 1:22 (1856-1921) a-y form toytodeolongegoneninaplhrvuhtorhuenypokyrioydiatoyprofhtoylegontos that declares a quotation with 'το ρηθεν υπο κυριου ... λεγοντος' also identifies the source with 'δια του προφητου' moreover fragment 1:23 1:23-34 (1922-1994, length 73) a-y form idoyhparuenosengastriejeikaitejetaiyionkaikalesoysintoonomaaytoyemmanoyhl matches LXX Isaiah 7:14+35 7:14 (14234-14304, length 71) a-y form idoyhparuenosengastriejeikaitejetaiyionkaikaleseistoonomaaytoyemmanoyhl unique in Old Testament differing by 8.33% providing an overall cover of 100.00%.
Another menu in the Statement Editor, Prove provides the option Parse
to perform a detailed check. First, a syntactical check is performed, and then,
several further checks are done, including all minor details of the entered statement.
For example, raw positions, passage lengths, fragment matches, overlaps, percentual data,
and uniqueness of an Old Testament passage are checked. You can try to change one
digit or one letter in the statement: you will see that most of such changes result
in an error.
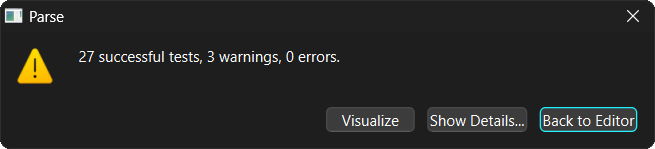
In the case of a successful parsing, the user can Visualize the statement.
By choosing this button, a GraphViz SVG output will be generated and displayed
in a new window. This can be freely resized. The displayed diagram follows the
same rules explained in former blog entries, but here is a short overview:
Unfortunately, in the current version there are no tooltips and there is no way to move the boxes. Maybe such features will be supported in a future version. In fact, GraphViz has no support for interactive change of position of the nodes, but tooltips are quite nicely supported. Hopefully, the Qt developers will continue their good work in improving the software to make these plans possible in the future.
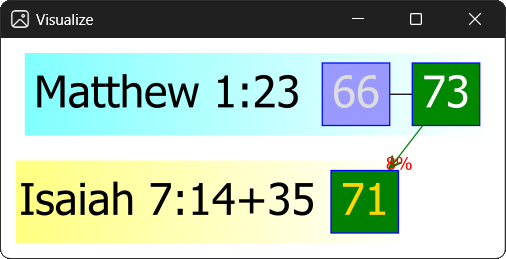
- The New Testament passage is shown in a cyan background, the corresponding Old Testament passages are shown in a yellow one.
- The Bible positions point to the first letters of the Greek texts. A plus sign means that some of the first letters are ignored in the given verse.
- The numbers in the rectangular boxes (they are usually squares) give the amount of Greek letters in a part of the passages.
- Introductory texts are put in blue boxes. If they declare that a quotation follows, or if they contain some relevant information on the source of the passage, then the box is somewhat darker.
- Green boxes always mean texts that are quotations or are quoted. They are always connected with a green arrow. A red percentual number shows if there is a difference between them, otherwise there is no number shown. In the Old Testament passages, a gold number means that the passage is unique in the whole Old Testament. Otherwise, all numbers are white in the green boxes. Intensity of the green boxes in the New Testament passage shows the percentual match linearly (the darkest green means verbatim match, the lightest green means no match). Unlike in former blog posts, the Old Testament boxes are always colored with the same dark green color to emphasize the origin.
- White boxes mean that the corresponding letters do not seem to be part of the quotation but they are something else: maybe some explanatory text or comments added by the author in the New Testament.
- Grey numbers are used if the letters appear before the given Bible position. This is usually shown in the introductory parts (or other comments) that precede the quotation.
Unfortunately, in the current version there are no tooltips and there is no way to move the boxes. Maybe such features will be supported in a future version. In fact, GraphViz has no support for interactive change of position of the nodes, but tooltips are quite nicely supported. Hopefully, the Qt developers will continue their good work in improving the software to make these plans possible in the future.
As a second example, here is the visualization diagram for
Matthew 2:6
(this time in light mode):
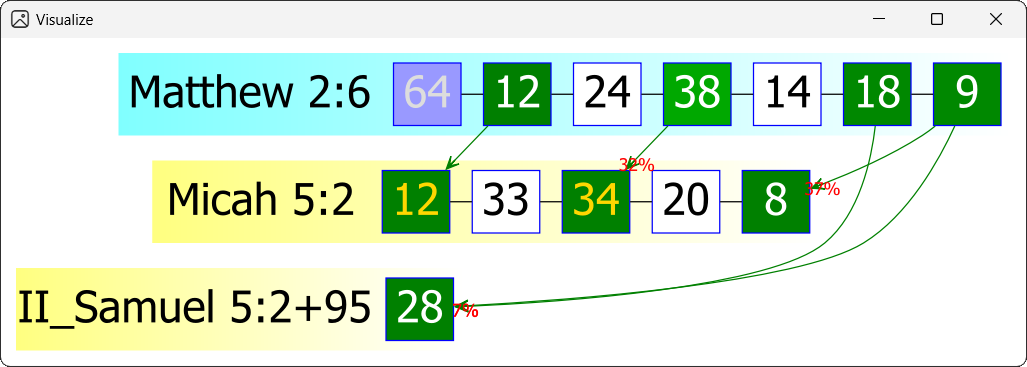
Clearly, this has a certain complexity, and the use of GraphViz is very beneficial.
Is this really a milestone?
I think, definitely yes. I can just refrain my former opinion on this:
By having an exact statement that collects all required pieces of information
by using reproducible data, we have a step forward towards scientific discussion.
Now, we have a set of more than 200 scientific statements, all of them checked
in a rigorous mechanical way, and everything is well-documented, by using industry standard methods.
To convince the user (and anyone) that here is something more
than random matching, can be shifted to a pure scientific level.
What next?
I plan to include the following improvements in the future versions (some of these
have already been addressed in newer bibref
versions
2025Jan04
and
2025Jan22):
- Linux and Mac versions.
- Update the HTML/WebAssembly version.
- Improve textual contents of infos, warnings and errors.
- Show line and column numbers in the Statement Editor.
- Show parse information in a larger window with colors and indicate the position of a possible issue in the Statement Editor as well.
- Show the formerly edited BRST file instead of choosing the same text on startup.
- GraphViz export (maybe via GraphViz Online, by providing a weblink that contains the whole code). Add tooltips to this version (and also the texts according to the boxes).
- Internationalized menu texts (first for Hungarian, then for German).
- Find a better font size (and better font) for Visualize, also for the percentual data.
Entries on topic internal references in the Bible
- Web version of bibref (12 January 2022)
- Order in chaos (17 January 2022)
- Reproducibility and imperfection (20 January 2022)
- A student of Gamaliel's (23 January 2022)
- Non-literal matches in the Romans (26 January 2022)
- Literal matches: minimal uniquity and maximal extension (31 January 2022)
- Literal matches: the minunique and getrefs algorithms (1 February 2022)
- Non-literal matches: Jaccard distance (2 February 2022)
- Non-literal matches in the Romans: Part 2 (3 February 2022)
- A summary on the Romans (5 February 2022)
- The Psalms (6 February 2022)
- The Psalms: Part 2 (7 February 2022)
- A classification of structure diagrams (15 February 2022)
- Isaiah: Part 1 (19 February 2022)
- Isaiah: Part 2 (26 February 2022)
- Isaiah: Part 3 (2 March 2022)
- Isaiah: Part 4 (7 March 2022)
- Isaiah: Part 5 (15 March 2022)
- Isaiah: Part 6 (23 March 2022)
- Isaiah: Part 7 (30 March 2022)
- A summary (7 April 2022)
- On the Wuppertal Project, concerning Matthew (17 July 2022)
- Matthew, a summary (25 July 2022)
- Isaiah, a second summary (31 July 2022)
- Long false positives (23 August 2022)
- A general visualization (25 August 2022)
- Stephen's defense speech (19 September 2022)
- Statistical Restoration Greek New Testament (31 July 2023)
- Qt version of bibref (11 March 2024)
- Statements on Bible references (5 August 2024)
- Statements on Bible references: Part 2 (2 January 2025)
- Statements connecting LXX and StatResGNT (23 January 2025)
- Deuterocanonical books in the bibref project (5 February 2025)
- Update to LXX 3.0: Part 2 (7 February 2025)
- An allusion on Palm Sunday (29 March 2025)
- Module LXX can be upgraded from 3.0 to 3.2 just with little pain (14 August 2025)
- bibref: German language support (23 August 2025)
- Statement diagrams based on LXX 3.2 (24 December 2025)

|
Zoltán Kovács Linz School of Education Johannes Kepler University Altenberger Strasse 69 A-4040 Linz |